Japan RepRap Festival 2026という3Dプリンタのイベントが5月30日と31日に開催された。去年が第1回で、そのレポートを読んで面白そうだと思い今回は2日目の31日に行ってみた。会場は東京流通センター(TRC)。
出展しているのは3Dプリンタのメーカー、代理店、フィラメントのメーカー、3Dプリンタを自作や改造している人、出力品を展示する人など。スポンサーと個人出展は明確には分けられておらず、ごちゃ混ぜ感がまたよかった。
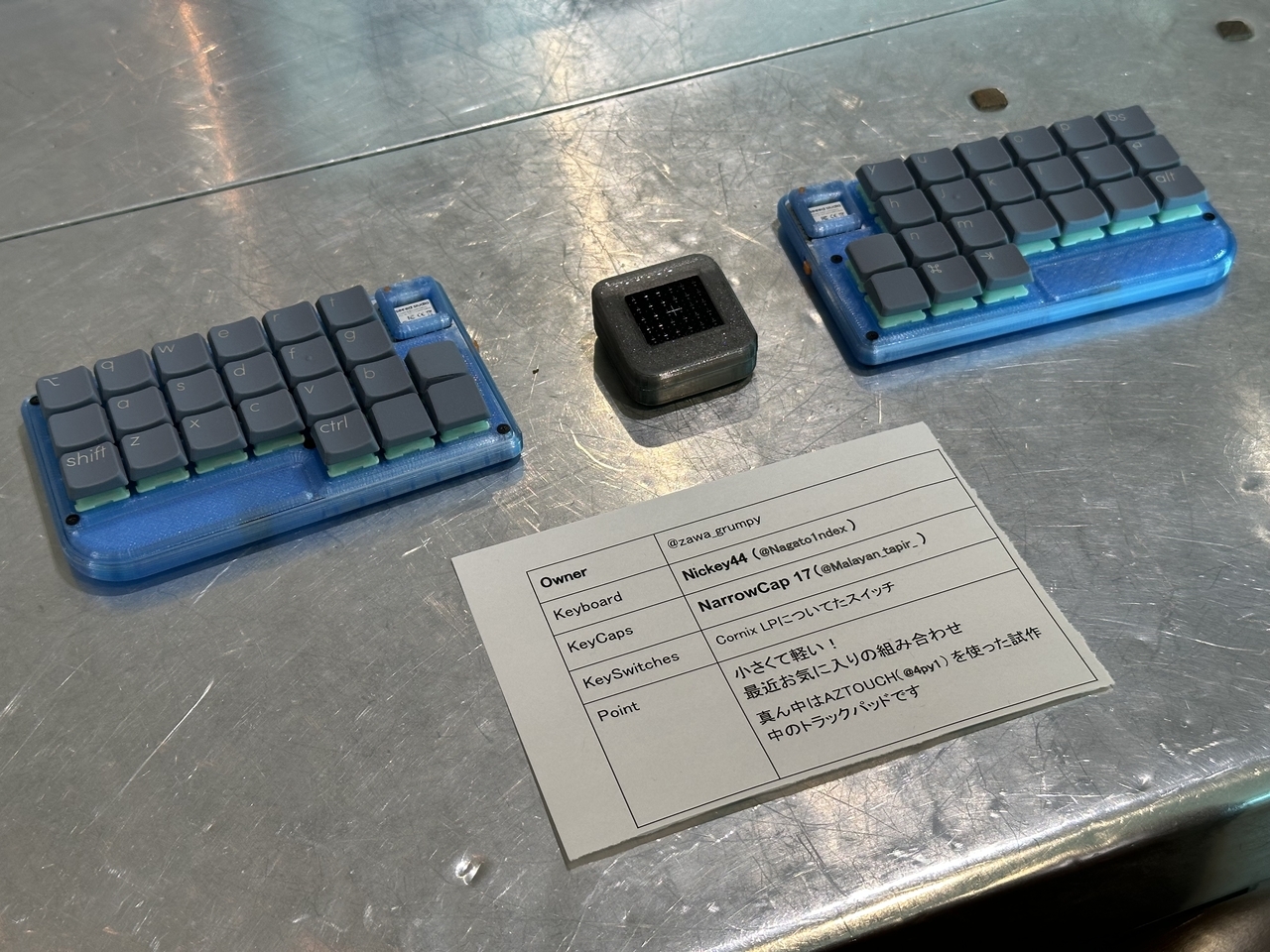
入口わきの壁に立てかけられているのは、メイカーチップをはめ込む大きなボード。よく見るとはめ込み禁止のところがあって、そこはドット絵のようにJRRF(Japan RepRap Festival)と読めるようになっている。

MakerChipは、3Dプリンター愛好家のために作られたカスタマイズ可能なトークンです。個性を表現するクリエイティブなアイテムであると同時に、自分の3Dプリント技術をアピール・紹介するための実用的なツールでもあります。
MakerChipとは? | Japan RepRap Festival 2026
ということで直径40ミリ、厚さ約3ミリのメイカーチップを持ち寄って、会場で配ったり交換したりする。QRコードを描いておけばPRになるし、凝ったデザインだったり複雑な造形だったり、歯車が回るなどのギミックがあったりもする。今はもう多色造形は当たり前なのだなあ。
- 会場の様子

いきなりドラゴンの全身着ぐるみがいた。うおおお(@uh_oh_oh_oh)氏製作。3Dプリンタでうろこなどのパーツを出力して組み上げている。

ドラゴンの顔はまばたきするのでとてもリアリティがある。これは中の人のまばたきを読み取ってサーボでまぶたを動かしているそうだ。まばたきのタイミングが人工的でないところもリアルさに貢献していると感じた。

こちらは第一セラモ(@daiichiceramo)の展示で、ステンレス入りのフィラメントの作例。金属3Dプリンタは業務用の何千万円もする専用機しかないが、これはご家庭のFDM式3Dプリンタで造形できる。ただし窯で焼くのはご家庭では無理で、第一セラモが業者を紹介してくれるという。写真中央のが出力した状態で、右のは焼いたあと。だいぶ縮んでいる。縮み方は一定なのでそれを見越して少し大きく造形するとのこと。写真左はいつものボート。焼いたあと研磨してピカピカになっていた。

フィラメントでは旭化成も面白いのを出していた。TPUなどよりずっと柔らかい「KARAKSA SEBS/CNF」。これも普通の3Dプリンタで出力できる。フィラメントの価格は500グラム15,000円とのことでかなり高いが、お金さえ出せばこういう柔らかい造形も可能というのは希望がある。

3Dプリンタで作ったものの展示の中から、しましまファブ(@shimashima_fab)の「ポチブクロボ」。ロボット型のポチ袋で、お札の顔の部分をロボの顔にできる。お札を取り出すにはちょっとしたパズルを解く必要があるそうだ。楽しい。

やまねくん(@nekundesign)氏は3Dプリンタのフィギュアを販売。ゼンマイを巻くとヘッドがジージー動く。かわいい。

ココポッサ(@cocopossa)氏のファンシーな展示。自分の世界観を3Dプリンタで自由に表現していてよい。今はこういうパステルカラーのフィラメントもあるんだな(塗装だったらスミマセン)。ここのほかにもコスプレのアイテムを出力しているというところもあった。

3Dプリンタとしては珍しいアーム形状というだけでなく、自分で移動もできる3Dプリンタ。ぼんじー(@bonjyy)氏作。これは理論上、出力面積を無限大にできるということなのでは?

一般的な3DプリンタはXYZの3軸で造形するが、Gear工房(@_gear_geek_)は5軸で動く3Dプリンタを出展。造形テーブルが傾くことで、サポート不要で複雑な形状を出力できる。

あっこれK800ですよね、と声が出たのがタラバガニー設計局(@mackee_w)のデルタ型3Dプリンタ。これうちにもありました。製作中の記事が「デルタ式3Dプリンタのキットを作る(途中経過) 」。2015年3月なのでもう11年前だ。うちのはこないだ人に譲ってしまった(「さらば3Dプリンタ
」。2015年3月なのでもう11年前だ。うちのはこないだ人に譲ってしまった(「さらば3Dプリンタ 」)。でもこの方は、10年前に買ったK800を今でも改造し続けている。パーツを交換していたら、最初から残っているのはフレームとモーターだけになったそう。テセウスの船だ。ベッドレベリングやKlipper対応だけでなく、多色造形もできるようにしていて現代の3Dプリンタらしくなっている。すごい。
」)。でもこの方は、10年前に買ったK800を今でも改造し続けている。パーツを交換していたら、最初から残っているのはフレームとモーターだけになったそう。テセウスの船だ。ベッドレベリングやKlipper対応だけでなく、多色造形もできるようにしていて現代の3Dプリンタらしくなっている。すごい。
JRRF1日目のブログも上がっていた。


これはなにを見てほしいのかというと、1枚目の写真の中央上で4種類のフィラメントを送り出している装置。bambulabのA1 miniという、お安くて精度がよい3Dプリンタなどで使える、多色造形のためのユニット「BMCU370C」である。純正の多色造形ユニット「https://jp.store.bambulab.com/products/ams-lite:AMS Lite」は単体で買うと34,800円だが、こちらは中華通販で1万円前後で買えるそうだ。さすが中国、売れると考えるとすぐ互換品が出てくるんだな。

どんどんおーぼ、どんどんおーぼじゃないか。昔「ログイン」という雑誌の「ヤマログ」コーナーのマスコットだったキャラクターが立体になっていた。「みなさまが生まれる前のキャラクター」とか書かれてる。確かに40年前だと多くの人にはそうなるか。年を取るものだ。
このように、3Dプリンタといってもいろいろなアプローチがあって、見ていて楽しいイベントだった。次回にも期待しちゃう。
とここで終わればめでたしなんだけれど、運営にはパンフレットについてお願いがある。アンケートのページは本稿執筆時点で準備中だったのでここに書いてしまおう。
パンフレットの後半には、個人参加のブース紹介ページが19ページある。1ページに6ブースあるから100以上のブースがここに掲載されている。

このページがとても使いにくかった。各ブースがどういう順序で並んでいるのかわからなかったからだ。ブースの識別コード順ではないしブースの五十音順でもない。会場での並び順でもないようだ。そして索引がないので、名前からブースの紹介を見たいときや識別コードだけわかるブースの紹介を見たいときは、19ページにわたる紹介ページをめくって見つけるしかない。これは不便。ぜひ改善をお願いしたい。










































































































")