最初にCMです
Stable Diffusionの解説書が販売中です。よろしくお願いいたします。いい本だと感じた方はAmazonにレビューを書いていただけますと幸いです。





img2imgのインペイントで画像を修正しよう
Stable Diffusionの「img2img」(画像とプロンプトから新しい画像を生成)の中には、「インペイント(inpaint)」という機能があります。マスクする範囲を指定して、そこだけ(またはそれ以外だけ)別の画像に入れ替えるというものです。『Stable Diffusion AI画像生成ガイドブック』では156ページ「3-11 インペイントで画像の一部を修正する」で機能を解説しています。
インペイントはどういうときに使うといいのか、いくつかのユースケースを紹介します。
余分な手足などの除去
txt2imgで出力した画像で、構図は申し分ないのに余分なものが描画されてしまうことがあります。手足が増えてしまうなどがその一例です。
下の画像はいい感じのが出ましたが、左上に謎の剣があるほか、中央の人物の足が3本あるように見えます。また左の人物の足下にも余分な足があります。これをインペイントで直しましょう。

(画像はメタデータ入りです。ブラウザから「PNG内の情報を表示(PNG Info)」へ直接ドラッグ&ドロップすると生成情報が読み込まれ、「txt2imgへ転送」ボタンをクリックするとtxt2imgで生成できるようになります)
- shot from below party of standing girls d & d characters sword shield armor stuff helmet
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 15714242, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Denoising strength: 0.7, Clip skip: 2, Hires upscale: 2.5, Hires upscaler: R-ESRGAN 4x+ Anime6B
txt2imgで画像を生成しました。画像の下の「inpaintに転送(Send to inpaint)」ボタンをクリックします。
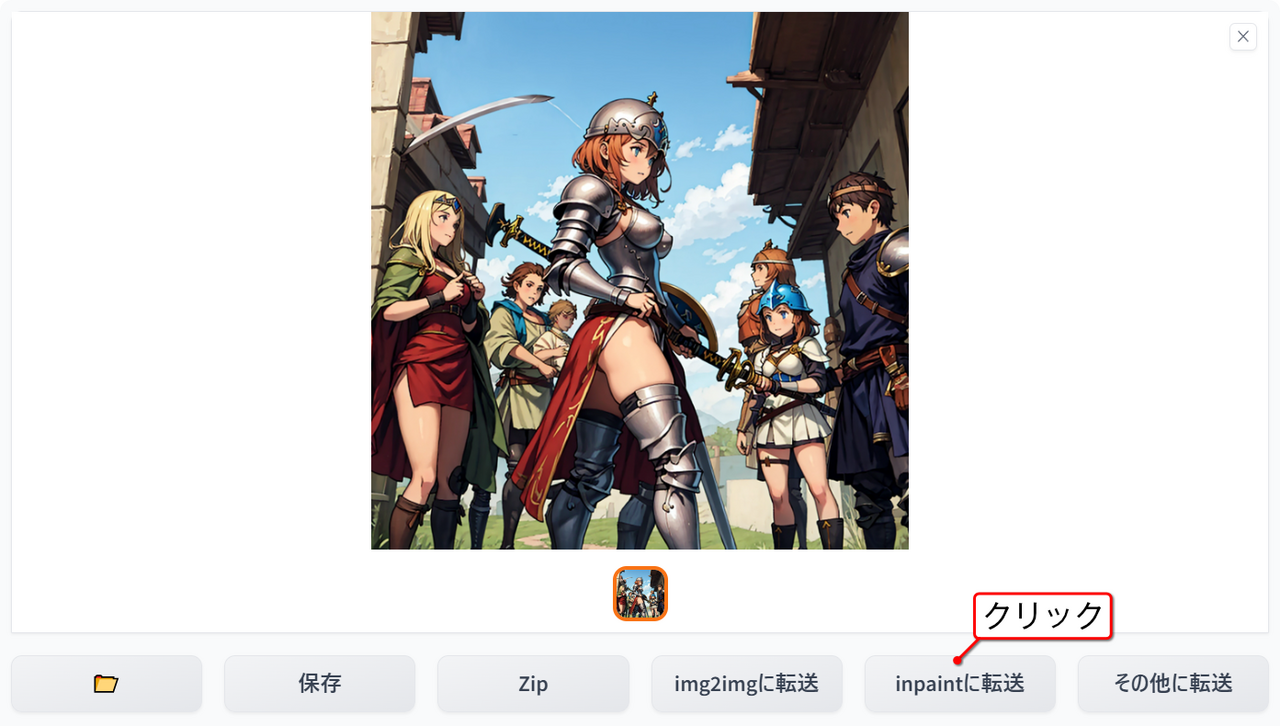
「img2img」タブの「inpaint」タブに先ほど生成した画像が読み込まれ、プロンプトやネガティブプロンプトなどもtxt2imgからコピーされます。
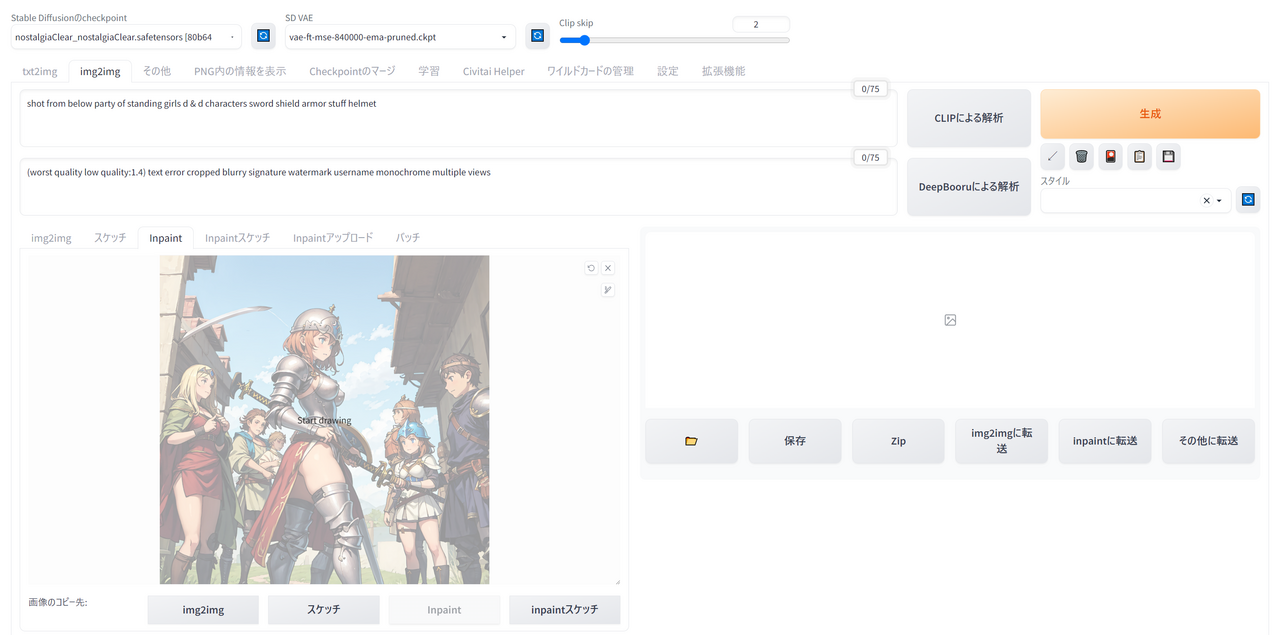
右上のボタン群は[×]が消去で、ほかにアンドゥとペンの太さの変更が可能です。
左上の剣と中央下部、そして左下の余分な足をマスクとして塗りつぶします。消しゴムにあたるツールはないので、塗りすぎたときはアンドゥするしかありません。一回の操作(マウスの場合一回のドラッグ)で広範囲を塗りつぶすと、アンドゥしたとき塗り直す範囲が広くなります。少しずつ塗っていくようにしましょう。
また塗る範囲は、消したい範囲からはみ出しても大丈夫です。余分なものを消すときは特に、少しはみ出ているくらいのほうがよい結果になります。
下のように塗りました。

塗ったのはこの範囲です。

インペイントの生成パラメータを設定します。ポイントとなるのはここです。
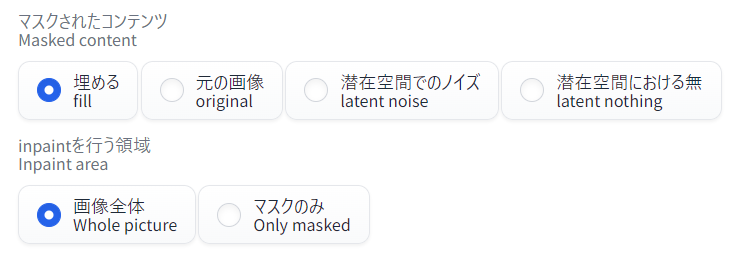
- マスクされたコンテンツ(Masked content)…「埋める(fill)」
- マスクされた領域を元の画像の色を参考にいったん塗りつぶし、それをもとに画像を生成します。元の画像の雰囲気を引き継ぎつつ異なる画像を生成し、その中に空中の剣や余分な足が描かれていないことを期待しています。
- inpaintを行う領域(Inpaint area)…「画像全体(Whole picture)」
- 画像全体を再生成し、その結果を元の画像へ貼り込みます。その際、マスクされた領域だけを切り出して元の画像の上にかぶせるイメージです。
- シード(seed)…「-1」
- 「inpaintに転送」した際に元の画像のシード値「15714242」が入っていますが、このままだと何度インペイントしても同じ画像が生成されます。ランダムな画像を生成する「-1」を指定します。
プロンプトやそのほかのパラメータはそのままにして「生成」ボタンをクリックしましょう。
何度か生成したところ、こんな画像が出ました。

- shot from below party of standing girls d & d characters sword shield armor stuff helmet
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 668721389, Size: 1280x1280, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Denoising strength: 0.7, Clip skip: 2, Mask blur: 4
3か所すべてがきれいに消えました。新しく描き込まれた部分も違和感はありません。
左から元の画像、新しい画像から切り出されたマスク部分、2つを重ねて出力された画像です。

(今回は3か所を同時に修正しましたが、1か所や2か所だけいい感じに修正されることが多くありました。それを改めて「inpaintに転送」し、修正されていない場所だけマスクし直してインペイントする方法もあります。インペイントで生成された画像をもう一度「inpaintに転送」する手順はこのあと解説します)
ディテールアップ
遠くにあって崩れ気味の顔をくっきりと描写させてみましょう。
下は512×512ピクセルで出力した画像です。画像の中で顔の占める割合が少なく、表情がよくわかりません。

- standing 1girl fullbody red coat outdoor
- Negative prompt: (hat hood:1.8) EasyNegative, (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 3169349441, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Clip skip: 2
高解像度補助(Hires. fix)で2.5倍の1,280×1,280ピクセルに拡大しました。表情がよくわかります。

- standing 1girl fullbody red coat outdoor
- Negative prompt: (hat hood:1.8) EasyNegative, (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 3169349441, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Denoising strength: 0.5, Clip skip: 2, Hires upscale: 2.5, Hires upscaler: R-ESRGAN 4x+ Anime6B
ここから、インペイントで顔をさらにきめ細かく描写してもらいます。画像の下の「Inpaintに転送(Send to inpaint)」ボタンをクリックします。
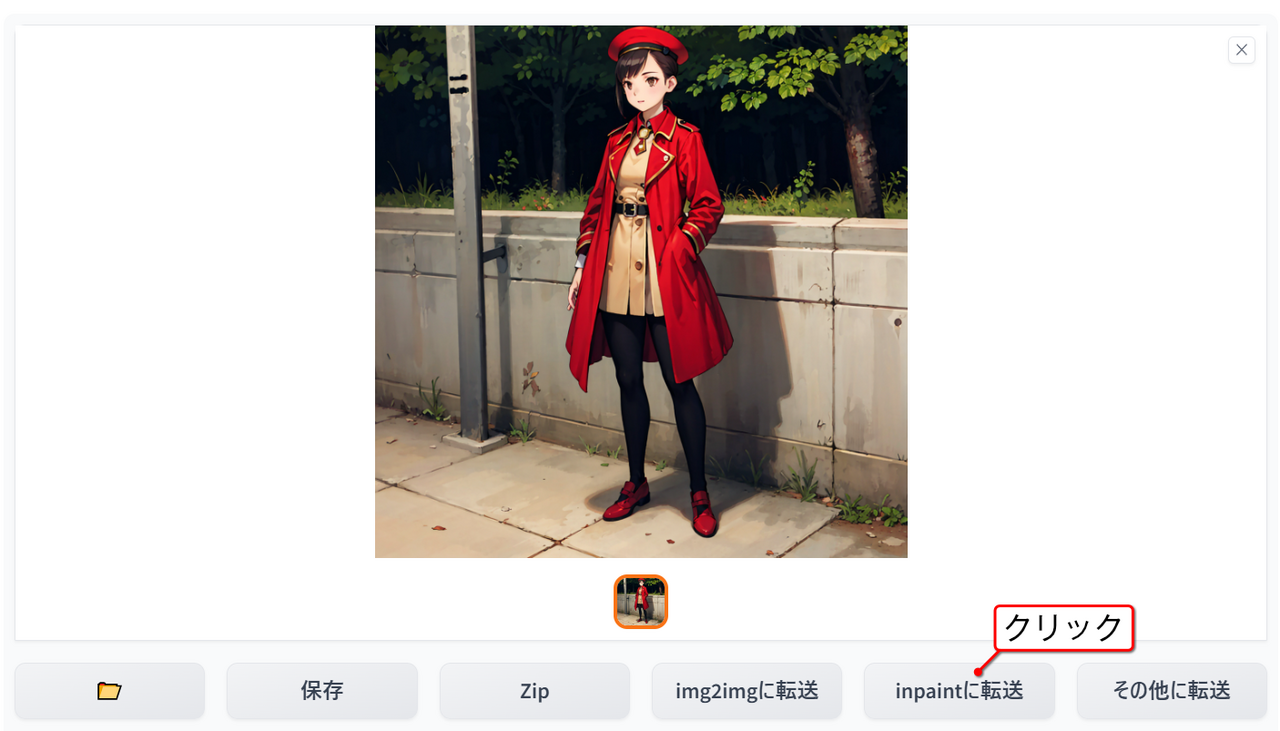
顔と帽子を塗りつぶします。

インペイントのパラメータを設定します。重要なのはこの2つです。
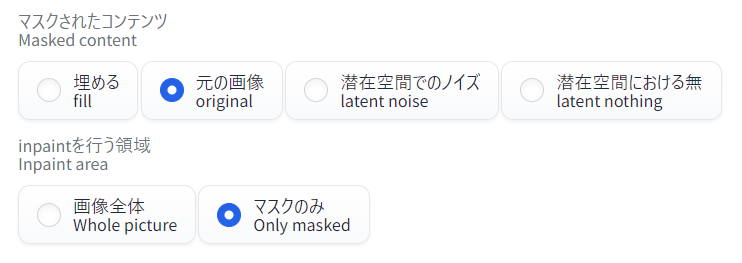
- マスクされたコンテンツ(Masked content)…「元の画像(original)」
- マスクされた領域の元の画像からimg2imgのようにして画像を生成します。
- inpaintを行う領域(Inpaint area)…「マスクのみ(Only masked)」
- マスクされた範囲をいったん拡大して画像を生成し、その結果を縮小して元の画像へ貼り込みます。
そのほかのパラメータはプロンプトやネガティブプロンプト、シード値も含めてすべて変更せず、そのまま「生成」しました。するとこうなります。

- standing 1girl fullbody red coat outdoor
- Negative prompt: (hat hood:1.8) EasyNegative, (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 2, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 3169349441, Size: 1280x1280, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Denoising strength: 0.5, Clip skip: 2, Mask blur: 4
顔を拡大すると、さらにきめ細かく描写されていることがわかります。

ポイントは、「inpaintを行う領域」の設定を「マスクのみ」にしていることです。
この設定で画像を生成すると、ライブプレビューにはマスクされた顔の周囲のみが表示されます。マスク部分(と「“マスクのみ”外側の余白」で設定された領域)だけを拡大して画像を生成するので、全身の画像よりきめが細かくなるのです。
- 「マスクのみ」の設定で画像を生成するとき、ライブプレビューに表示される画像

こうして生成されたマスク周辺の画像を元の大きさに縮小し、マスクの範囲を切り出して貼り付けるのが「マスクのみ」のインペイントです。
左からインペイント前、「マスクのみ」で生成された画像、マスク部分の切り抜き、元の画像に合わせて縮小された画像、元の画像に重ねて出力された画像です。

表情差分
「表情差分」とは、顔の絵の一部分を差し替えた場所のことです。同じ顔で口や目の部分を差し替えて、同じ場面で別の表情を表現します。
この表情差分を作るのもインペイントが向いています。まずこのような画像を出力しました。

- face of girl
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 2616579653, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Clip skip: 2
例によって「inpaintに転送」ボタンでimg2imgのInpaintへコピーします。まずは口を差し替えて笑顔にしてみましょう。口の周囲を少し大きめにマスクします。

インペイントのパラメータは最初の作例と同じにします。
- マスクされたコンテンツ(Masked content)…「埋める(fill)」
- inpaintを行う領域(Inpaint area)…「画像全体(Whole picture)」(ここを「マスクのみ」にすると、口だけディテールが細かくなり違和感が出ます)
- シード(seed)…「-1」
プロンプトに「smile(笑顔)」を追加して生成しました。

- face of girl smile
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1515158880, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Denoising strength: 0.75, Clip skip: 2, Mask blur: 4
次は笑い方を強くしてみます。[×]ボタンをクリックして「Inpaint」タブの画像とマスクをクリアしてから、先ほど生成された画像の下にある「inpaintに転送」ボタンをクリックします。
[×]ボタンで画像とマスクを消去するのは、「Inpaint」タブへ画像を転送すると一見マスクが上書きされてなくなったように見えますが、実は見えないだけで残っているためです。
マスクは目を塗りつぶします。

インペイントのパラメータは上と同じで、プロンプトの「smile」を「laugh closing eyes」にしました。

- face of girl laugh closing eyes
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 776585904, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear_nostalgiaClear, Denoising strength: 0.75, Clip skip: 2, Mask blur: 4
これで、最初の画像から2枚の表情差分を作ることができました。

インペイントの設定
マスクの画像も保存しておきたいときは、「設定」の「画像/グリッド画像の保存(Saving images/grids)」にある「inpaintingで、グレースケールマスクを保存する(For inpainting, save a copy of the greyscale mask)」をオンにします。
- 保存されるグレースケールマスクの例

マスクされた部分がどう変化したかがわかる画像を保存したいときは、同じ場所にある「inpaintingで、マスクされた合成箇所を保存する(For inpainting, save a masked composite)」をオンにします。
- 保存される合成箇所の画像の例

マスクをペイントソフトなどで作成し、画像ファイルとして読み込ませることもできます。マスクしたい部分を白く塗った画像を用意し、「Inpaintアップロード」タブにインペイントする画像とマスクの画像をアップロードします。あとは「Inpaint」タブと同じようにパラメータを指定し、「生成」ボタンをクリックすればインペイントされます。
おまけ
ところでこの記事の最初の画像を出力したプロンプトは好みの画像が出やすくて、プロンプトを少し変えながら作例に使える画像を探しつつこれもいい、これもいいとなりました。

- party of standing girls d & d characters sword shield armor
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 2505153224, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear, Denoising strength: 0.7, Clip skip: 2, Hires upscale: 2.5, Hires upscaler: R-ESRGAN 4x+ Anime6B
以下はプロンプトの冒頭に「shot from below」をつけています。
- Seed: 477250127

- Seed: 3802791941

- Seed: 2162398145

- Seed: 1591183280

- Seed: 2985495877

- Seed: 4253026792

- shot from below party of standing girls d & d characters sword shield armor stuff helmet
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: -1, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear, Denoising strength: 0.7, Clip skip: 2, Hires upscale: 2.5, Hires upscaler: R-ESRGAN 4x+ Anime6B
以下はプロンプトの冒頭を「shot from above」にしました。
- Seed: 3643923879

- shot from above party of standing girls d & d characters sword shield armor stuff helmet
- Negative prompt: (worst quality low quality:1.4) text error cropped blurry signature watermark username monochrome multiple views
- Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: -1, Size: 512x512, Model hash: 80b64299af, Model: nostalgiaClear, Denoising strength: 0.7, Clip skip: 2, Hires upscale: 2.5, Hires upscaler: R-ESRGAN 4x+ Anime6B
そのほかの画像はサムネイルを掲載します。クリックするとメタデータつきの大きい画像が表示されます。






















一部の画像は余分なものが描かれていたり、顔が鮮明でなかったりします。今回解説したインペイントの練習台にどうぞご利用ください。
(おまけ2)ダイナミックプロンプトについて
上の画像のプロンプトは、冒頭になにも書かない、「shot from below」を書く、「shot from above」を書くという3種類で出力しました。生成時にこれらをランダムに出すようまとめて指定すると、3種類のプロンプトを切り替えつつ出力する手間が省けます。
プロンプトをランダムに出すには、「拡張機能」タブからインストールできる「Dynamic Prompts」の拡張機能を使います。プロンプトに「{|shot from below|shot from above}」のように書くと、何も書かない、「shot from above」か「shot from below」を書くという3種類のプロンプトがランダムに選ばれ、画像が生成されます。詳しくはプロジェクトページをご覧ください。
- Dynamic Promptsのプロジェクトページ
adieyal/sd-dynamic-prompts: A custom script for AUTOMATIC1111/stable-diffusion-webui to implement a tiny template language for random prompt generation

また、拡張機能のインストール方法は『Stable Diffusion AI画像生成ガイドブック』の80ページ「2-4 SD/WebUIを日本語化する」で解説しています。
本の第3章では、この記事のような調子でStable Diffusionのさまざまな機能を解説しています。ぜひ手に取ってご覧ください。